Mehdi Nemlaghi
Some blog posts
The Cloud Embedding Series
Repeatable and Serverless embedding endpoint deployment with SageMaker, Bedrock and CDK
Previously, on the cloud embedding series
After an intro, we evaluated pre-trained embeddings and selected a state-of-the-art model in part 1. In part 2 we discovered an easy way to fine-tune an embedding with LoRA and SageMaker.
Now it’s time to expose our embedding system to the real-world. The real-world needs an infrastructure , a set of machines getting stuff done. And, since we care about your organization budget, we’ll explore two avenues:
- either use Bedrock embeddings
- either deploy embedding endpoints in a serverless way with SageMaker Endpoint!
And, since we think about production success, we’ll also adopt a repeatable way so that you can easily deploy (and destroy) an embedding infrastructure with Cloud Development Kit (CDK).
The fastest option: Amazon Bedrock
There is a first good news. Back in part one, we already knew that, with Amazon Bedrock, the AWS go-to option to build serverless generative AI already has multiple embeddings. So you don’t need to provision any infrastructure. What you would need instead is accessing the model on your account.
We already encountered an example in part1, but here is another brief code snippet highlighting how you can use Bedrock embeddings. As you can see, it is as easy as invoking any AWS service, henceforth reducing headaches and aspirin costs… The following compares two sentences, one in French (to be honest, Frenglish :-) ) and one in English, that are similar.
import boto3
import json
import numpy as np
brclient=boto3.Session(region_name='us-east-1', profile_name="<YOUR_AWS_CONFIG_PROFILE>").client('bedrock-runtime')
inputs = {"texts":["Word embeddings lead to really powerful applications", "Les word embeddings permettent des applications puissantes"], "input_type":"search_query"}
response = brclient.invoke_model(modelId="cohere.embed-multilingual-v3", body = json.dumps(inputs))
r = response['body'].read().decode('utf8')
embeddings = json.loads(r)['embeddings']
e1,e2 = embeddings[0], embeddings[1]
sim = np.dot(e1,e2)/ (np.linalg.norm(e1)*np.linalg.norm(e2))
print(sim)
On SageMaker: why AWS CDK is beneficial for your AI/ML project
In case you want to choose another pretained embedding model, then read further and see how CDK can infuse huge benefits in your ML project! As seen in Part 1, SageMaker Jumpstart allows to select and deploy pretrained models in a quick manner. As a warm-up, we’re going to get a bit further by automating this task with CDK.
The challenge
Despite the current AI hype, when it comes to production, we still encounter asperities. According to a recent McKinsey study, only 36% of ML projects go beyond pilot stage. Worse: the same study evaluates the likelihood of successful scale to only 15%.
That’s why, ML savvy people might need to think of their ML projects, at their inception, not only as sole models, but as comprehensive systems that include - but aren’t limited to - models: interactions, cost, infrastructure, user experience, latency requirements… This is hard because ML is not your classical software engineering practice.
The solution: IaC with CDK!
Fortunately there’s a solution: CDK. We’ll apply CDK for effectively deploying a a SageMaker embedding endpoint. AWS CDK is an open-source toolbox allowing builders to define and provision cloud resources with AWS CloudFormation. It belongs to the infrastructure as Code practice. A more detailed tutorial of CDK can be found here. Here are some benefits of using CDK :
- development costs 💰: automatic cloud definition and provisioning means freeing yourself from handling manual components time to market
- ⏰: When you define your modeling early in the process, likelihood of successful model deployment will increase.
- tight integration with AWS components: CDK often provides native constructs that we can directly leverage within our application. If not available, CDK custom resources can help us in extending our application with our own logic.
Cherry on top 🍒: CDK is available in Python 🐍. Let’s do it!
The CDK journey: what we need to do
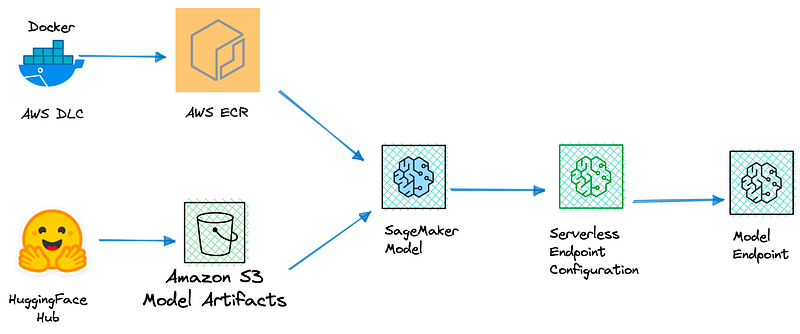
💡 Code - including details for installing CDK are available at your convenience here, but we’ll walk through its main parts!
Build a SageMaker Model
A SageMaker model is characterized by two main components:
- on one hand, after selecting (and optionally fine-tuned) a model, we are provided with a set of model artefacts, mainly embodied with model parameters, either pre-trained or fine-tuned. For instance, after a training job, model parameters are stored as archive within an S3 bucket.
- on the other hand, there’s an environment, which means the framework (PyTorch, TensorFlow, HuggingFace…) , artefacts and scripts that allow us to effectively use the model during prediction - or inference - time. This environment is manifested by a Docker container.
Picking up one Hugging Face Container
Depending on your needs, SageMaker is flexible and allows three types of containers:
- Built-in algorithms: these are owned by AWS and help customers in quickly begin their ML journey
- Bring your own container (BYOC): this option let you build your own Docker container and use it for both training and inference. This situation happens in very specific situations.
- Prebuilt SageMaker Docker images: these environments are based upon popular deep learning frameworks and dependencies. Their Docker registry path is available here.
In the pre-trained embedding case, which prebuilt image we can start with ?
AWS Deep Learning Containers are a set of public Docker images for training, processing and predicting ML workloads that are available in Elastic Container Registry.
Here’s a convenient way to retrieve SageMaker image URIs with SageMaker SDK: let’s begin with the latest transformers library with its 4.28.1 version with the newest pytorch2.0.0 flavor, GPU-configured. For instance, should our region is located in London, simply perform:
from sagemaker import image_uris
s= image_uris.retrieve(framework='huggingface'
,region='eu-west-2'
,version='4.28.1'
, image_scope="inference"
, base_framework_version="pytorch2.0.0"
, instance_type="ml.g4dn.xlarge")
print(s)
This simple snippet will output the ECR Image URI for the relevant prebuilt SageMaker Docker image.
⚠️ As we’ll observe below, we need a lightweight image, because, when deploying a Serverless endpoint, maximum size of the container image is 10GB .
Indeed, in AWS DLC, the above image is embodied by PyTorch 2.0.0 with HuggingFace transformers Framework, in the huggingface-pytorch-inference repository name, associated with tag: 2.0.0-transformers4.28.1-gpu-py310-cu118-ubuntu20.04
Let’s check at its image size with AWS CLI.
aws ecr describe-images --repository-name huggingface-pytorch-inference \
--region eu-west-2 --registry-id 763104351884 \
--image-ids imageTag="2.0.0-transformers4.28.1-gpu-py310-cu118-ubuntu20.04" \
--query 'imageDetails[*].{size: imageSizeInBytes, tags: imageTags}'
[
{
"size": 6554689045,
"tags": [
"2.0.0-gpu-py310",
"2.0-transformers4.28-gpu-py310-cu118-ubuntu20.04-v1",
"2.0-gpu-py310-cu118-ubuntu20.04-v1",
"2.0.0-transformers4.28.1-gpu-py310-cu118-ubuntu20.04-v1.2",
"2.0.0-transformers4.28.1-gpu-py310-cu118-ubuntu20.04",
"2.0-gpu-py310",
"2.0.0-gpu-py310-cu118-ubuntu20.04",
"2.0.0-transformers4.28.1-gpu-py310-cu118-ubuntu20.04-v1.2-2023-07-24-20-35-44",
"2.0-transformers4.28-gpu-py310-cu118-ubuntu20.04"
]
}
]
Results indicate that size is above 6GB. Nothing abnormal due to all CUDA dependencies. Let’s search for a more suitable image 🔎: let’s check for the same PyTorch version, but with CPU counterpart.
aws ecr describe-images --repository-name huggingface-pytorch-inference \
--region eu-west-2 --registry-id 763104351884 \
--image-ids imageTag="2.0.0-transformers4.28.1-cpu-py310-ubuntu20.04" \
--query 'imageDetails[*].{size: imageSizeInBytes, tags: imageTags}'
[
{
"size": 6075113228,
"tags": [
"2.0.0-cpu-py310-ubuntu20.04",
"2.0.0-transformers4.28.1-cpu-py310-ubuntu20.04",
"2.0-transformers4.28-cpu-py310-ubuntu20.04-v1",
"2.0.0-cpu-py310",
"2.0.0-transformers4.28.1-cpu-py310-ubuntu20.04-v1.2-2023-07-24-20-35-45",
"2.0.0-transformers4.28.1-cpu-py310-ubuntu20.04-v1.2",
"2.0-cpu-py310",
"2.0-cpu-py310-ubuntu20.04-v1",
"2.0-transformers4.28-cpu-py310-ubuntu20.04"
]
}
]
Still high. Nothing abnormal as well, since, looking at the Dockerfile, AWS integrated multiple extra heavyweight libraries, such as diffusers.
Let’s lower the version of PyTorch.
aws ecr describe-images --repository-name huggingface-pytorch-inference \
--region eu-west-2 \
--registry-id 763104351884 \
--image-ids imageTag="1.13.1-transformers4.26.0-cpu-py39-ubuntu20.04" \
--query 'imageDetails[*].{size: imageSizeInBytes, tags: imageTags}'
[
{
"size": 1451073006,
"tags": [
"1.13.1-transformers4.26.0-cpu-py39-ubuntu20.04-v1.3",
"1.13.1-cpu-py39-ubuntu20.04",
"1.13.1-transformers4.26.0-cpu-py39-ubuntu20.04-v1.3-2023-07-04-00-15-16",
"1.13-cpu-py39-ubuntu20.04-v1",
"1.13.1-cpu-py39",
"1.13-transformers4.26-cpu-py39-ubuntu20.04-v1",
"1.13-cpu-py39",
"1.13.1-transformers4.26.0-cpu-py39-ubuntu20.04",
"1.13-transformers4.26-cpu-py39-ubuntu20.04"
]
}
]
This repository tag seems to be lightweight compared to the previous ones. It might be a perfectly suited one. Therefore, we choose this one for a model name.
image = sagemaker.ContainerImage.from_dlc("huggingface-pytorch-inference",
"1.13.1-transformers4.26.0-cpu-py39-ubuntu20.04",
account_id="763104351884")
If your model emerges from a training job, then your model artifacts are stored within an S3 bucket. You can fetch their S3 URI in a couple of manners: either via the console: in SageMaker>Training jobs, select your training job and find the Output section, or via AWS CLI
YOUR_TRAINING_JOB_NAME="YourTrainingJobName"
aws sagemaker describe-training-job \
--training-job-name YOUR_TRAINING_JOB_NAME \
--query 'ModelArtifacts.S3ModelArtifacts'
If your embedding model is directly pre-trained, we don’t have model artifacts stored in S3 yet. No worries ! We’ll do 3 steps to do it:
- we’ll use
huggingface_hublibrary: a lightweight library destined to download model snapshots - we’ll archive the model in the
tar.gzformat - we’ll push the
tar.gzformat in the desired S3 uri.
Here’s a code snippet on how to perform it.
from pathlib import Path
import os
import shutil
from huggingface_hub import snapshot_download
# set HF_HUB_ENABLE_HF_TRANSFER env var to enable hf-transfer for faster downloads
os.environ["HF_HUB_ENABLE_HF_TRANSFER"] = "1"
HF_MODEL_ID="sentence-transformers/all-mpnet-base-v2"
# create model dir
model_tar_dir = "YOUR_MODEL_DIRECTORY"
shutil.rmtree(model_tar_dir, ignore_errors = True)
model_tar_dir.mkdir(exist_ok=True)
Then, a couple of bash commands do the trick:
model_tar_dir = "<YOUR_MODEL_DIRECTORY>"
YOUR_DESIRED_S3_LOCATION="<s3 location of archive, suffixed with model.tar.gz>"
cd model_tar_dir
tar zcvf model.tar.gz *
aws s3 cp model.tar.gz YOUR_DESIRED_S3_LOCATION
… But you were supposed to tell about PRETRAINED models! I don’t have even a bucket yet.
Here I come. Pre-trained models in HuggingFace have to be populated yet.
Challenges: #Challenge A- How can I automatically create a bucket?
Easy 🥊. Just import the stack that creates an S3 bucket, with the right removal policies included as parameters.
from aws_cdk import aws_s3 as s3
#[...]
self.default_bucket = s3.Bucket(self, id="bucket123",
bucket_name=bucket_name
, removal_policy=RemovalPolicy.DESTROY
, auto_delete_objects=True)
Challenge B - How can I populate the bucket with pretrained model artifacts!
Slightly less easy 🥊🥊 . We’re going to leverage three solutions together: HuggingFace Hub, AWS Lambda and CDK Custom Resources.
- Step 1: we create a Lambda function - container runtime - that downloads model artefacts from HuggingFace Hub into
/tmpdirectory of Lambda runtime, tars the model in the right .tar.gz and sends it to S3. Just as if we already have an existing bucket. - Step 2: when both bucket and Lambda Function are created by the stack - we can ensure this by adding dependencies - we invoke this Lambda Function with the relevant parameters.
Can we invoke Lambda Function during resource creation?
Well, this is where AWS Custom Resources come to the rescue. It creates a Lambda function invoking every piece of code you’d like. Including AWS API calls, including Lambda invokation. Technically, we’ll have a Lambda wrapped into another one.
Does it work for every model artefact?
It worked for both E5 and BGE model families in their large versions! However, due to maximum timeout to 15 minutes, one can consider building an AWS Batch construct instead of AWS Lambda construct and run this for larger models. Now, either way, we have a container and artifacts, and are ready to move on. Way to go!
SageMaker Serverless Inference primer.
What and why?
SageMaker Serverless Inference is an online model deployment with SageMaker without the hassle of configuring, sizing and managing resources. In my humble opinion, it pushes the cloud logic to further step: you pay only for your endpoint consumers requests, and it’s also a very convenient way for ML-savvy people to own their project and to allow them to focus on ML development and deployment, without losing time on rightsizing instances.
It’s better suited for workloads that have irregular traffic while tolerating some flexibility in latency.
How to configure it?
SageMaker Serverless inference is scalable to your needs. It’s characterized by two main parameters:
- Memory Size: between 1024M and 6144M, by increments of 1024M. Obviously, this option allows you to allocate a RAM size to your serverless endpoint, but also compute ressources proportional to them.
- Number of concurrent invocations: how many requests can be handled simultaneously
- (New) provisioned concurrency: feature that allows to minimize time requested to spin up an instance upon a new invocation.
Memory Size is a way of scaling vertically, while number of concurrent executions will scale horizontally. The only current limitation of Serverless Inference is that GPU instance types are not supported, but…
💡 The whole point of this series is to highlight the fact that, most of the time, we don’t need GPU for performant embedding systems !
In SageMaker, configuration is handled via the well-named endpoint configuration. SageMaker CDK supports a serverless configuration.
cfn_endpoint_config = sm_cfn.CfnEndpointConfig(self, "MyCfnEndpointConfig",
endpoint_config_name=Fn.join("", [model_name, "-endpoint-config"],
production_variants=[sm_cfn.CfnEndpointConfig.ProductionVariantProperty(
initial_variant_weight=1,
model_name=model.model_name,
variant_name="AllTraffic",
serverless_config=sm_cfn.CfnEndpointConfig.ServerlessConfigProperty(
max_concurrency=1,
memory_size_in_mb=6144))])
And now the endpoint…
We’re almost there 🧘🏻♀️ ! Thanks to our endpoint configuration, creating an Endpoint with CDK is just one line of code away
cfn_endpoint = sm_cfn.CfnEndpoint(self, "MyCfnEndpoint",
endpoint_config_name=cfn_endpoint_config.endpoint_config_name,
endpoint_name=Fn.join("", [model_name, "-endpoint"]))
Recap
This post explored deploying a repeatable and serverless embedding endpoint leveraging Bedrock, SageMaker, AWS CDK, and Bedrock. Key points:
👉🏽 Amazon Bedrock: Get started quickly with self-managed, pre-trained embedding models. No infrastructure needed.
👉🏽 SageMaker Jumpstart: Automate deployment of pre-trained models using AWS CDK.
👉🏽 The CDK Journey: Build and deploy custom SageMaker models, including optimizing container size by evaluating different AWS Deep Learning Containers, preparing model artifacts, creating S3 buckets, and leveraging Lambda and AWS CDK Custom Resources.
👉🏽 Serverless Inference: Configure and create serverless endpoints using memory size and concurrent invocations.
👉🏽 API Gateway (Optional): Expose deployed endpoints via API Gateway and Lambda functions to invoke Bedrock/SageMaker runtime clients.
By following this approach and carefully selecting lightweight containers, you can deploy state-of-the-art embeddings in a repeatable, serverless, and cost-effective manner, focusing on empowering your technology for machine learning. Next, we’ll store and query embeddings, thanks to Bedrock Knowledge Bases, and we’ll explore various vector DB selection options!